RDMA: Why It Matters for AI Infrastructure
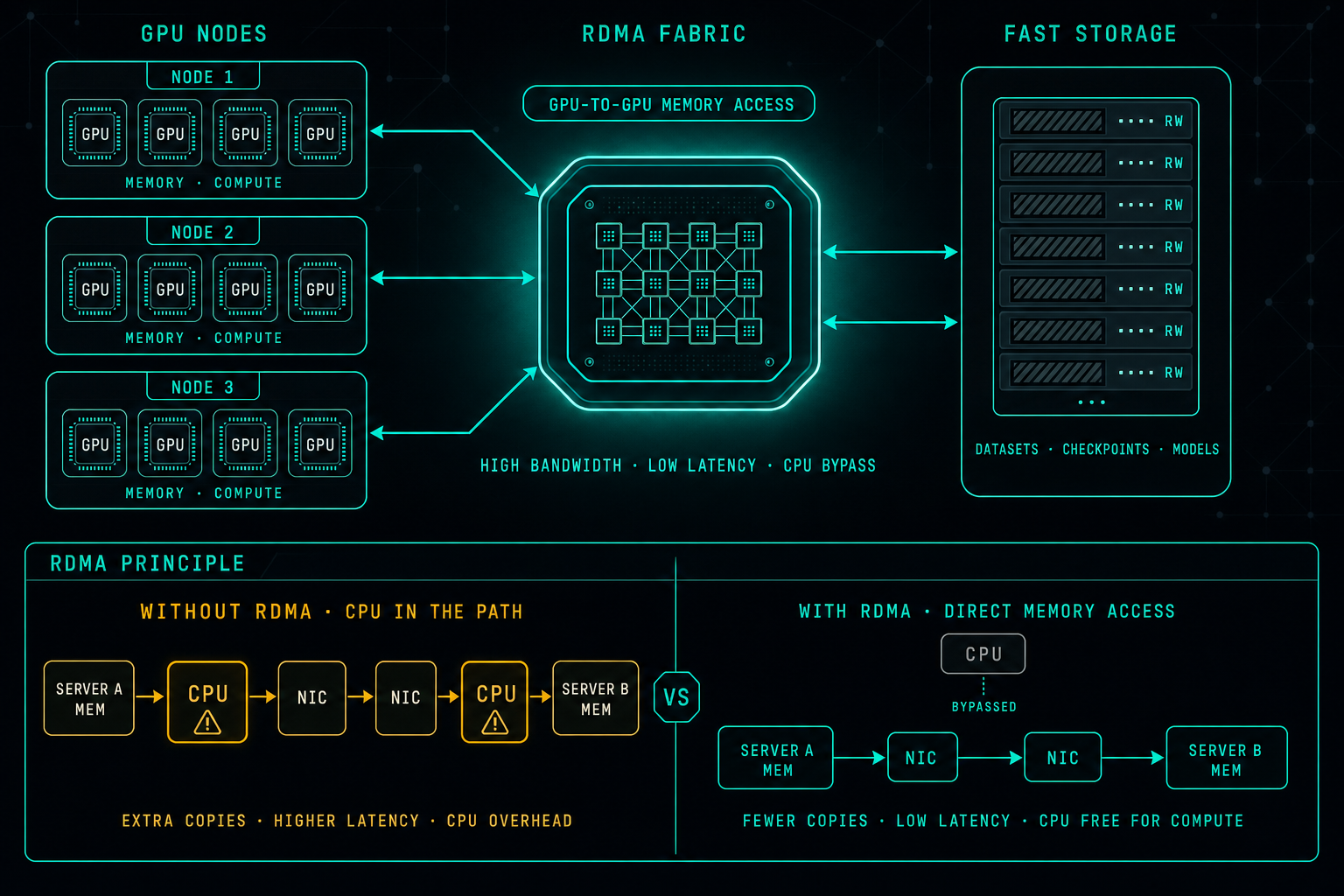
Modern AI workloads run across many GPUs, many servers, and large datasets. At that scale the network is just as important as the compute. RDMA lets one server access memory on another with very low latency and minimal CPU involvement, so GPUs can spend time on math instead of waiting on the network. It is not a checkbox, but it is the difference between a fast GPU cluster and an expensive one that is mostly idle.
AI workloads are no longer running on one server only.
Modern AI environments often use multiple GPUs, multiple servers, large datasets, distributed training, and fast storage. In this kind of environment, the network becomes just as important as the compute.
This is where RDMA becomes important.
RDMA stands for Remote Direct Memory Access. In simple words, it lets one server access memory on another server with very low latency and without involving the CPU too much.
That means data can move faster between systems.
For AI workloads, this matters a lot.
When GPUs are training a model or working together on large data, they constantly need to exchange information. If the network is slow, or if the CPU becomes a bottleneck, the GPUs may wait instead of working.
That is expensive.
RDMA helps reduce latency, lower CPU overhead, and improve data movement between servers, GPUs, and storage systems.
It is especially important for distributed training, high-performance storage, large model workloads, and AI clusters where many nodes need to work together.
The main idea is simple.
In AI infrastructure, fast GPUs are not enough.
The network must be fast enough to keep them busy.
RDMA helps AI systems move data with less delay, better efficiency, and higher performance across the cluster.
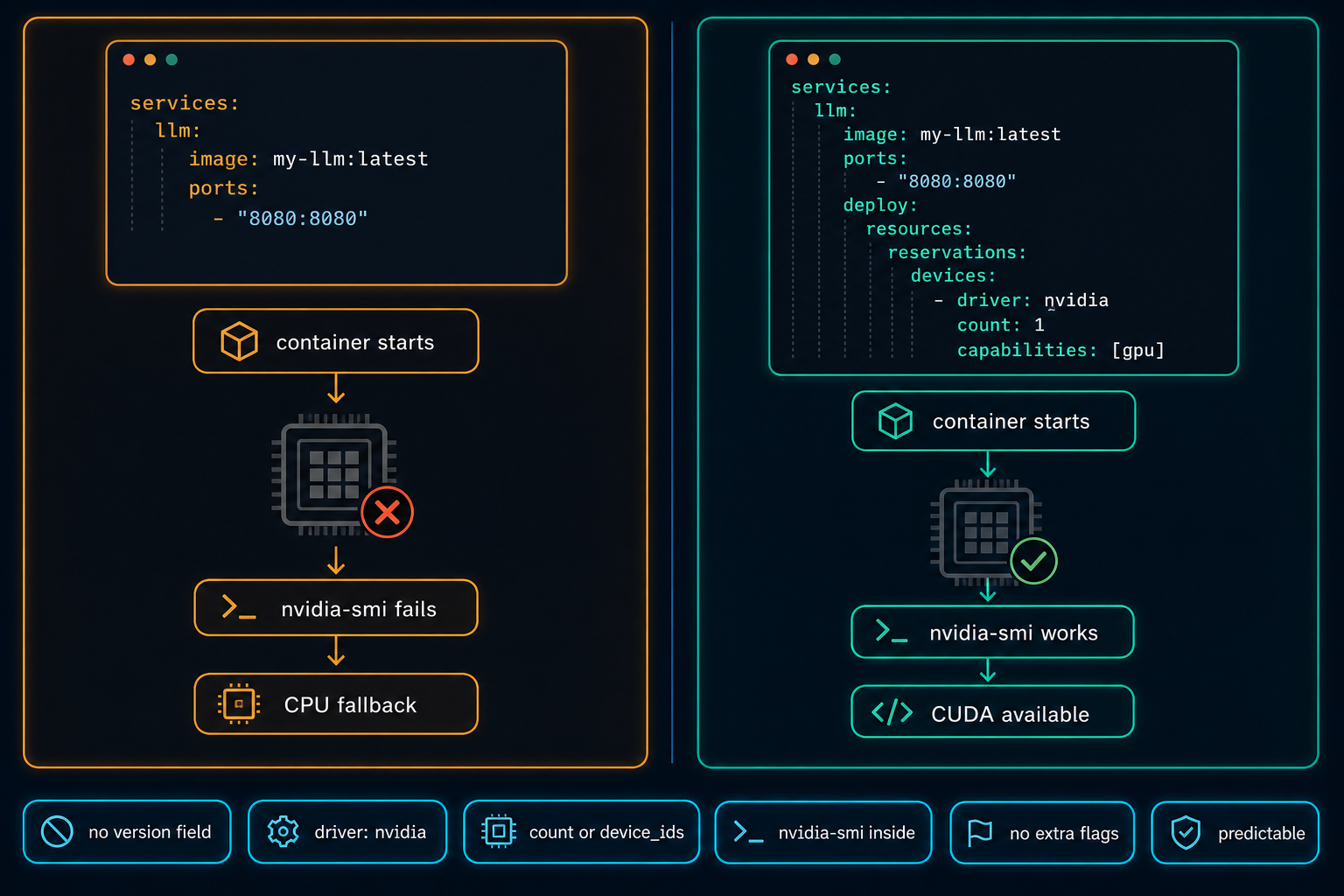
Docker Compose Does Not Automatically Use the GPU
On Linux GPU servers, Docker Compose does not use the NVIDIA GPU automatically. The service starts, nothing obviously fails, and the workload quietly falls back to CPU. The fix is a few lines in the compose file, but only if you know to look for them.
Read article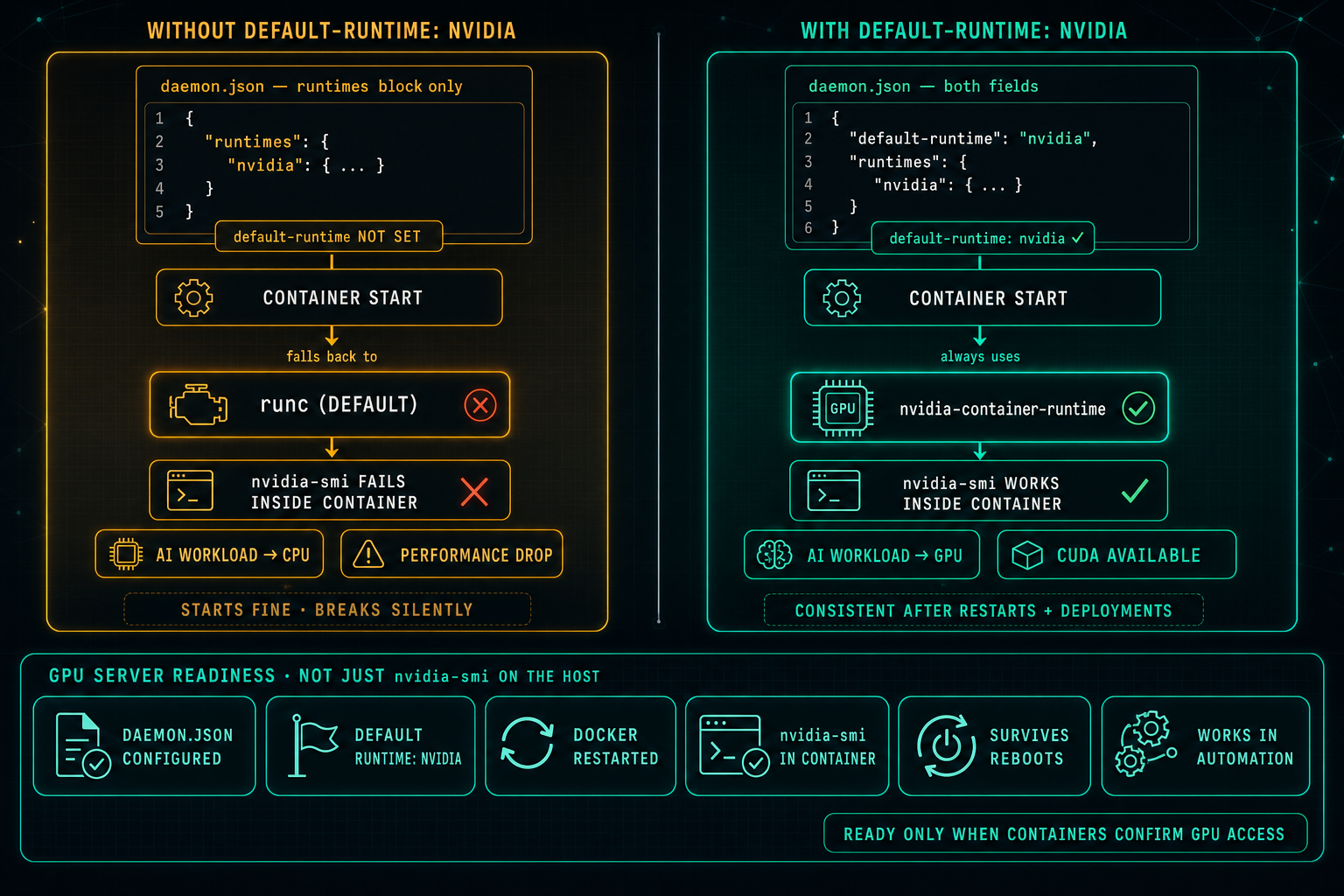
Docker Default Runtime: Keep GPU Containers on NVIDIA
On Linux GPU servers, Docker can know about the NVIDIA runtime and still not use it. If default-runtime is missing from daemon.json, every container falls back to runc, nvidia-smi fails inside the container, AI workloads drop to CPU, and the problem looks like an application issue when it is really a one-line configuration gap.
Read article